
If you utilize Apache Spark, you probably have a few applications that consume some data from external sources and produce some intermediate result, that is about to be consumed by some applications further down the processing chain, and so on until you get a final result.
We suspect that because we have a similar pipeline with lots of processes like this one:

Click here for a bit larger version
Each rectangle is a Spark application with a set of their own execution parameters, and each arrow is an equally parametrized dataset (externally stored highlighted with a color; note the number of intermediate ones). This example is not the most complex of our processes, it’s fairly a simple one. And we don’t assemble such workflows manually, we generate them from Process Templates (outlined as groups on this flowchart).
So here comes the One Ring, a Spark pipelining framework with very robust configuration abilities, which makes it easier to compose and execute a most complex Process as a single large Spark job.
And we just made it open source. Perhaps, you’re interested in the details.













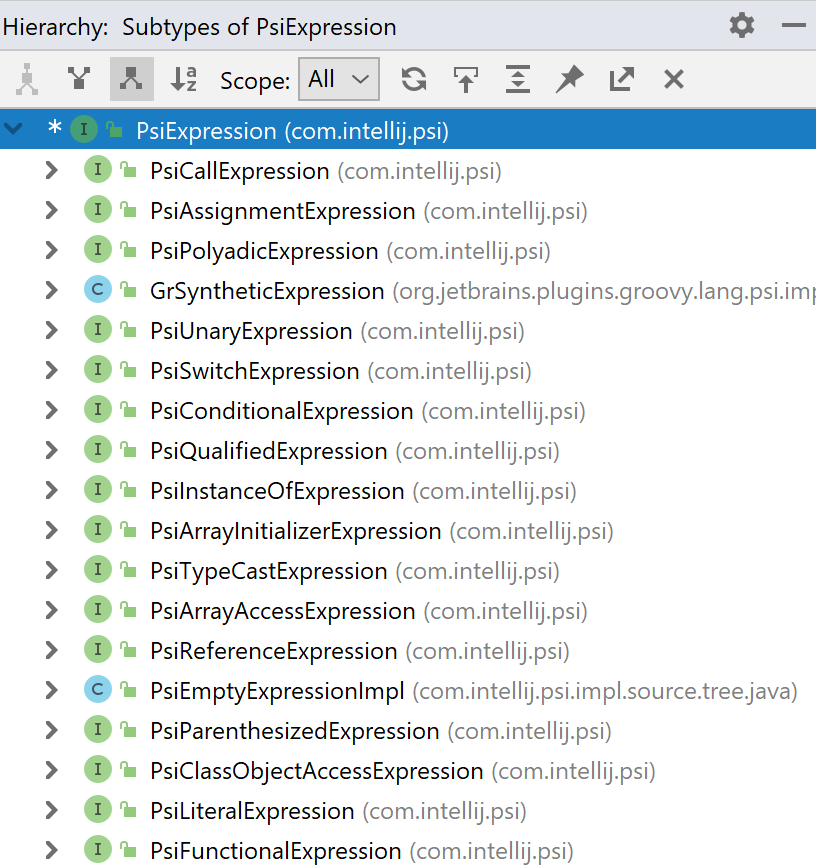 Code search and navigation are important features of any IDE. In Java, one of the commonly used search options is searching for all implementations of an interface. This feature is often called Type Hierarchy, and it looks just like the image on the right.
Code search and navigation are important features of any IDE. In Java, one of the commonly used search options is searching for all implementations of an interface. This feature is often called Type Hierarchy, and it looks just like the image on the right.