
Teaching is hard! Finding a way to explain ideas and concepts, finding an approach to each individual among your students, each having a unique mind and learning capabilities. Being patient and creative, friendly but respective, kind but fair. You have to understand complex stuff and be able to present them in the simplest of ways. There are so many things that you must balance and consider in your work. Teachers, you are heroes, the every-day heroes! With this heroic work comes a responsibility. A responsibility of keeping yourself accountable for your student’s education. Some teachers forget about that and stay oblivious to the mistakes they are making. We’ve compiled a list of 9 Reasons Why Students Don’t Want You as a Teacher. We sincerely hope that it will help you to self-reflect, better connect with your students and achieve better results during your lessons.
Playing with Nvidia's New Ampere GPUs and Trying MIG
11 min

Every time when the essential question arises, whether to upgrade the cards in the server room or not, I look through similar articles and watch such videos.
Channel with the aforementioned video is very underestimated, but the author does not deal with ML. In general, when analyzing comparisons of accelerators for ML, several things usually catch your eye:
- The authors usually take into account only the "adequacy" for the market of new cards in the United States;
- The ratings are far from the people and are made on very standard networks (which is probably good overall) without details;
- The popular mantra to train more and more gigantic models makes its own adjustments to the comparison;
The answer to the question "which card is better?" is not rocket science: Cards of the 20* series didn't get much popularity, while the 1080 Ti from Avito (Russian craigslist) still are very attractive (and, oddly enough, don't get cheaper, probably for this reason).
All this is fine and dandy and the standard benchmarks are unlikely to lie too much, but recently I learned about the existence of Multi-Instance-GPU technology for A100 video cards and native support for TF32 for Ampere devices and I got the idea to share my experience of the real testing cards on the Ampere architecture (3090 and A100). In this short note, I will try to answer the questions:
- Is the upgrade to Ampere worth it? (spoiler for the impatient — yes);
- Are the A100 worth the money (spoiler — in general — no);
- Are there any cases when the A100 is still interesting (spoiler — yes);
- Is MIG technology useful (spoiler — yes, but for inference and for very specific cases for training);
Toxic Comments Detection in Russian
17 min

Currently, social network sites tend to be one of the major communication platforms in both offline and online space. Freedom of expression of various points of view, including toxic, aggressive, and abusive comments, might have a long-term negative impact on people’s opinions and social cohesion. As a consequence, the ability to automatically identify and moderate toxic content on the Internet to eliminate the negative consequences is one of the necessary tasks for modern society. This paper aims at the automatic detection of toxic comments in the Russian language. As a source of data, we utilized anonymously published Kaggle dataset and additionally validated its annotation quality. To build a classification model, we performed fine-tuning of two versions of Multilingual Universal Sentence Encoder, Bidirectional Encoder Representations from Transformers, and ruBERT. Finetuned ruBERT achieved F1 = 92.20%, demonstrating the best classification score. We made trained models and code samples publicly available to the research community.
Machine learning in browser: ways to cook up a model
12 min
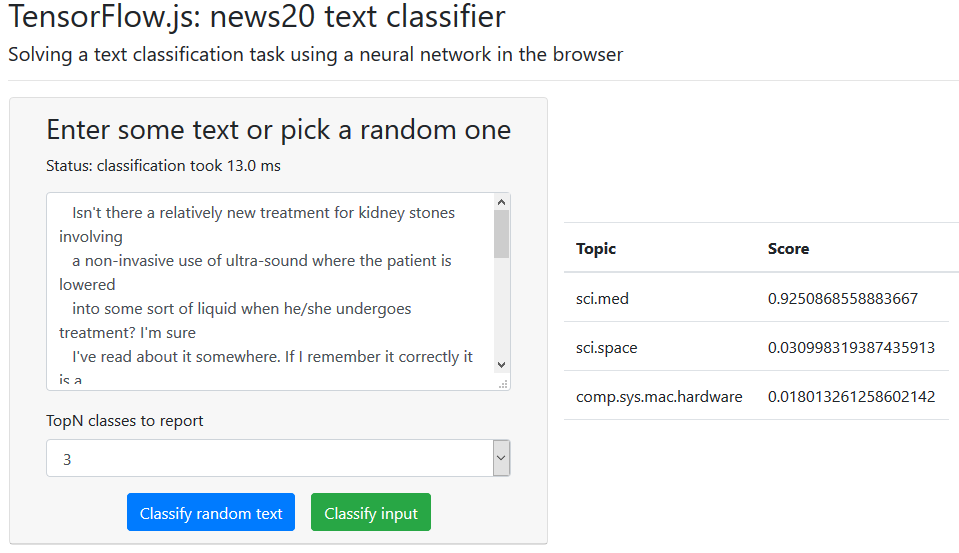
With ML projects still on the rise we are yet to see integrated solutions in almost every device around us. The need for processing power, memory and experimentation has led to machine learning and DL frameworks targeting desktop computers first. However once trained, a model may be executed in a more constrained environment on a smartphone or on an IoT device. A particularly interesting environment to run the model on is browser. Browser-based solutions may be used on a wide range of devices, desktop and mobile, online and offline. The topic of this post is how to prepare a model for the in-browser usage.
This post presents an end-to-end implementations of a model creation in Python and Node.js. The end goal is to create a model and to use it in a browser. I'll use TensorFlow and TensorFlow.js as main frameworks. One could train a model in Python and convert it to JS. Alternative is to train a model directly in javascript, hence omitting the conversion step.
I have more experience in Python and use it in my everyday work. I occasionally use javascript, but have very little experience in the contemporary front-end development. My hope from this post that python developers with little JS experience could use it to kick start their JS usage.
InterSystems IRIS – the All-Purpose Universal Platform for Real-Time AI/ML
22 min
Author: Sergey Lukyanchikov, Sales Engineer at InterSystems
We will start from the examples that we faced as Data Science practice at InterSystems:
Challenges of real-time AI/ML computations
We will start from the examples that we faced as Data Science practice at InterSystems:
- A “high-load” customer portal is integrated with an online recommendation system. The plan is to reconfigure promo campaigns at the level of the entire retail network (we will assume that instead of a “flat” promo campaign master there will be used a “segment-tactic” matrix). What will happen to the recommender mechanisms? What will happen to data feeds and updates into the recommender mechanisms (the volume of input data having increased 25000 times)? What will happen to recommendation rule generation setup (the need to reduce 1000 times the recommendation rule filtering threshold due to a thousandfold increase of the volume and “assortment” of the rules generated)?
- An equipment health monitoring system uses “manual” data sample feeds. Now it is connected to a SCADA system that transmits thousands of process parameter readings each second. What will happen to the monitoring system (will it be able to handle equipment health monitoring on a second-by-second basis)? What will happen once the input data receives a new bloc of several hundreds of columns with data sensor readings recently implemented in the SCADA system (will it be necessary, and for how long, to shut down the monitoring system to integrate the new sensor data in the analysis)?
- A complex of AI/ML mechanisms (recommendation, monitoring, forecasting) depend on each other’s results. How many man-hours will it take every month to adapt those AI/ML mechanisms’ functioning to changes in the input data? What is the overall “delay” in supporting business decision making by the AI/ML mechanisms (the refresh frequency of supporting information against the feed frequency of new input data)?
Modern Google-level STT Models Released
2 min

We are proud to announce that we have built from ground up and released our high-quality (i.e. on par with premium Google models) speech-to-text Models for the following languages:
- English;
- German;
- Spanish;
You can find all of our models in our repository together with examples, quality and performance benchmarks. Also we invested some time into making our models as accessible as possible — you can try our examples as well as PyTorch, ONNX, TensorFlow checkpoints. You can also load our model via TorchHub.

Как с помощью HUAWEI ML Kit самостоятельно создать апплет для фото на документы
5 min
Общая информация
В предыдущей статье мы рассказали о том, как создать камеру для улыбок с помощью HUAWEI ML Kit. В этот раз я собираюсь представить вам новую функцию HUAWEI ML Kit.
Вас когда-нибудь просили на учебе или работе принести фотографию определенного размера с цветным фоном для документов? В большинстве случаев у человека не окажется под рукой подходящей фотографии. Однажды в институте нам решили оформить персональные пропуска, но фотостудия оказалась закрыта. Тогда я сфотографировался на телефон, использовав простыню в качестве фона. И получил выговор от преподавателя. Но с помощью инструмента HUAWEI ML Kit вы сможете интегрировать SDK для сегментации изображений в ваше приложение и разработать апплет, чтобы создавать фото на документы самостоятельно и решить проблему отсутствия нужных фотографий.
Самое главное, что этот SDK абсолютно бесплатный и работает на всех телефонах на базе Android.
Разработка апплета для фото на документы самостоятельно
1. Подготовка
1.1 Добавьте репозиторий Maven Huawei в файл на уровне проекта build.gradle
Откройте файл build.gradle в корневом каталоге вашего проекта Android Studio.
Objects Representations for Machine Learning system based on Lattice Theory
5 min
This is a fourth article in the series of works (see also first one, second one, and third one) describing Machine Learning system based on Lattice Theory named 'VKF-system'. The program uses Markov chain algorithms to generate causes of the target property through computing random subset of similarities between some subsets of training objects. This article describes bitset representations of objects to compute these similarities as bit-wise multiplications of corresponding encodings. Objects with discrete attributes require some technique from Formal Concept Analysis. The case of objects with continuous attributes asks for logistic regression, entropy-based separation of their ranges into subintervals, and a presentation corresponding to the convex envelope for subintervals those similarity is computed.

Mathematics of Machine Learning based on Lattice Theory
7 min
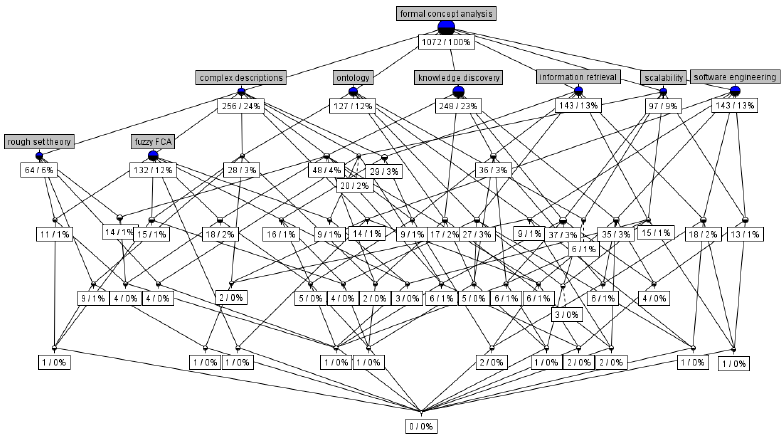
This is a third article in the series of works (see also first one and second one) describing Machine Learning system based on Lattice Theory named 'VKF-system'. It uses structural (lattice theoretic) approach to representing training objects and their fragments considered to be causes of the target property. The system computes these fragments as similarities between some subsets of training objects. There exists the algebraic theory for such representations, called Formal Concept Analysis (FCA). However the system uses randomized algorithms to remove drawbacks of the unrestricted approach. The details follow…
Machine Learning CPython library 'VKF'
14 min
Previous article describes a web server for Machine Learning system 'VKF' based on Lattice Theory. This paper is an attempt to explain details of using the CPython library directly. We reproduce working sessions of experiments on datasets 'Mushroom' and 'Wine Quality' from UCI Machine Learning repository. The structures of input files are discussed too.

How to find an English teacher. Part 2
4 min
This is a continuation of story about using Data Science for finding an English teacher. If you have not read it yet - there is an opportunity to become familiar with it
Briefly - we had information about language teachers and tried to apply some basic ideas using pandas and our expectations. Unfortunately we got stuck on the third step, because there is not enough information for resolving our the last requirements - we need not more 3 candidates at the end.
Disclaimer
It is an approach based on my own experience and can be unsuitable to your point of view, ideas, or principles.
Web server for Machine Learning 'VKF-solver'
20 min
Nowadays most people identify Machine Learning with training of various kinds of neural networks. At the beginning there were fully connected networks, then convolutional and recurrent networks replace them, now there exist a quite exotic variants of networks such that GAN and LTSM networks.
Their training requires constantly increasing volume of samples, and they also do not be able to explain why a particular decision was made. Structural approaches to Machine Learning avoiding these drawbacks exist, the software implementation of one of which is described in the article. This is an English translation of original post by the author.

Their training requires constantly increasing volume of samples, and they also do not be able to explain why a particular decision was made. Structural approaches to Machine Learning avoiding these drawbacks exist, the software implementation of one of which is described in the article. This is an English translation of original post by the author.
Critical Transcendence: .NET SDK and Apache Spark
5 min
When Alex Garland’s series Devs (on FX and Hulu) came out this year, it gave developers their own sexy Hollywood workup. Who knew that coders could get snarled into murder plots and love triangles just for designing machine learning programs? Or that their software would cause a philosophical crisis? Sure, the average day of a developer is more code writing than murder but what a thrill to author powerful new program.

Machine Learning & Big Data: Let’s Find The Relationship Between Them
4 min

Machine learning is indeed a famous word among technologies. Today we will relate it with another famous term that is Big data. Both these have become Buzz words these days. Let’s here find out their meaning individually.
Big data is known as the process in which we collect and analyze the large volume of data sets (called Big Data) which helps in discovering useful hidden patterns and other information such as customer choices, market trends which is really beneficial for the organizations to remain informed and customer-oriented business decisions.
Four Ways Quantum Computing Will Change Artificial Intelligence Forever
4 min
If science were a dating app, quantum physics and machine learning probably wouldn’t be a match. They’re from completely different fields and often require completely different backgrounds and skills. But, throw in a little quantum computing and, suddenly, that science-matchmaking app becomes Tinder and the attraction between the two is palpable.

(Credit: cmo.adobe.com/articles/2017/5/how-will-artificial-intelligence-impact-business-tlp-ptr.html#gs.5zlifl)
Even though the extent of change that quantum computing will unleash on AI is up for debate, many experts now more than suspect that quantum computing will definitely alter AI at some level. Analysts from bank holding company BBVA, for example, point toward the natural synergy between quantum computing and AI as reasons why quantum machine learning will eventually best classical machine learning.
“Quantum machine learning can be more efficient than classic machine learning, at least for certain models that are intrinsically hard to learn using conventional computers,” says Samuel Fernández Lorenzo, a quantum algorithm researcher who collaborates with BBVA’s New Digital Businesses area. “We still have to find out to what extent do these models appear in practical applications.”
COVID YAAA! or Yet Another Analyze Attempt
11 min

Hello, Habr!
About a month ago, I had a feeling of constant anxiety. I began to eat poorly, sleep even worse, and constantly read to a ton of news about the pandemic. Based on them, the coronavirus either captured, or liberated our planet, was either a conspiracy of world governments, or the vengeance of the pangolin, the virus either threatened everyone at once, or personally me and my sleeping cat…
Hundreds of articles, social media posts, youtube-telegram-instagram-tik-tok (yes, I sin) content of varying degrees of content quality did not lead me to anything but an even greater sense of anxiety.
But one day I bought buckwheat decided to end it all. As soon as possible!
DeepCode: Outside Perspective
7 min

Recently DeepCode, which is a static analyzer based on machine learning, began to support checking of C and C++ projects. And now we can find out the differences between the results of the classic and the machine-learning static analysis.
How does strange code hide errors? TensorFlow.NET Analysis
15 min
Static analysis is an extremely useful tool for any developer, as it helps to find in time not only errors, but also suspicious and strange code fragments that may cause bewilderment of programmers who will have to work with it in the future. This idea will be demonstrated by the analysis of the TensorFlow.NET open C# project, developed for working with the popular TensorFlow machine learning library.
Five Methods For Database Obfuscation
20 min
ClickHouse users already know that its biggest advantage is its high-speed processing of analytical queries. But claims like this need to be confirmed with reliable performance testing. That's what we want to talk about today.
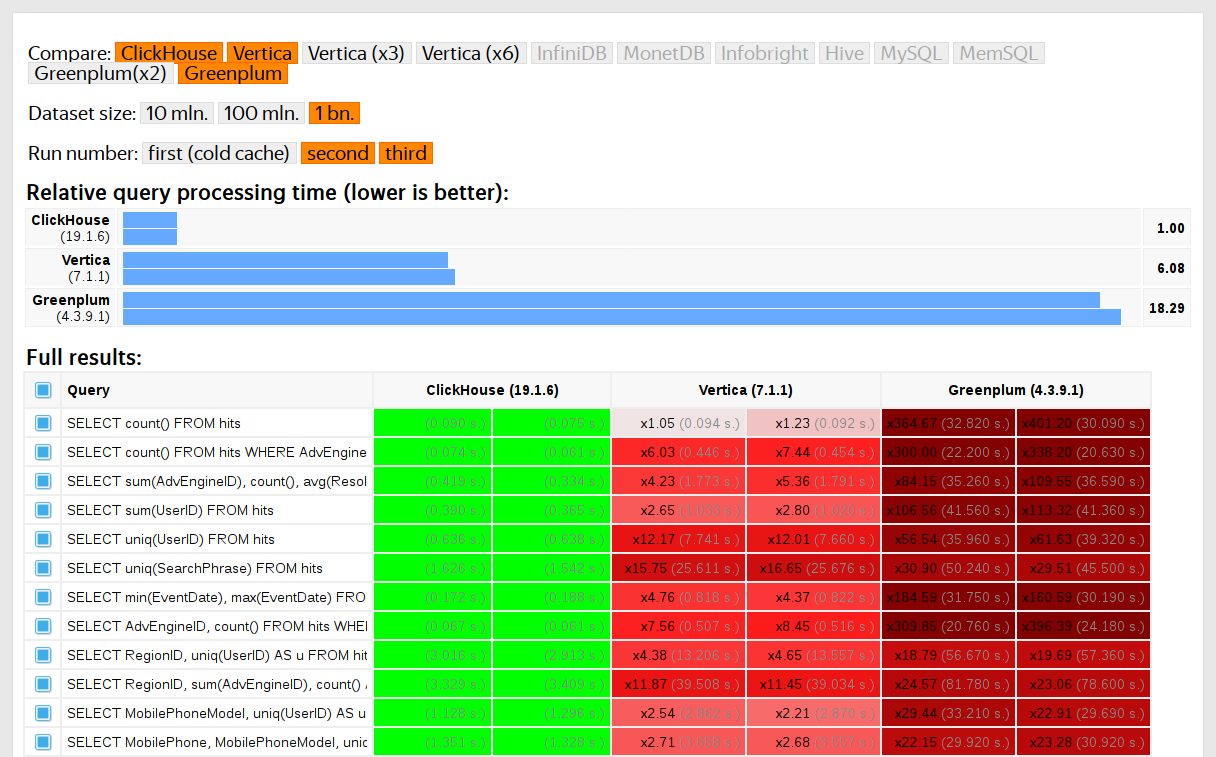
We started running tests in 2013, long before the product was available as open source. Back then, just like now, our main concern was data processing speed in Yandex.Metrica. We had been storing that data in ClickHouse since January of 2009. Part of the data had been written to a database starting in 2012, and part was converted from OLAPServer and Metrage (data structures previously used by Yandex.Metrica). For testing, we took the first subset at random from data for 1 billion pageviews. Yandex.Metrica didn't have any queries at that point, so we came up with queries that interested us, using all the possible ways to filter, aggregate, and sort the data.
ClickHouse performance was compared with similar systems like Vertica and MonetDB. To avoid bias, testing was performed by an employee who hadn't participated in ClickHouse development, and special cases in the code were not optimized until all the results were obtained. We used the same approach to get a data set for functional testing.
After ClickHouse was released as open source in 2016, people began questioning these tests.
We started running tests in 2013, long before the product was available as open source. Back then, just like now, our main concern was data processing speed in Yandex.Metrica. We had been storing that data in ClickHouse since January of 2009. Part of the data had been written to a database starting in 2012, and part was converted from OLAPServer and Metrage (data structures previously used by Yandex.Metrica). For testing, we took the first subset at random from data for 1 billion pageviews. Yandex.Metrica didn't have any queries at that point, so we came up with queries that interested us, using all the possible ways to filter, aggregate, and sort the data.
ClickHouse performance was compared with similar systems like Vertica and MonetDB. To avoid bias, testing was performed by an employee who hadn't participated in ClickHouse development, and special cases in the code were not optimized until all the results were obtained. We used the same approach to get a data set for functional testing.
After ClickHouse was released as open source in 2016, people began questioning these tests.
Machine Learning in Static Analysis of Program Source Code
27 min
Machine learning has firmly entrenched in a variety of human fields, from speech recognition to medical diagnosing. The popularity of this approach is so great that people try to use it wherever they can. Some attempts to replace classical approaches with neural networks turn up unsuccessful. This time we'll consider machine learning in terms of creating effective static code analyzers for finding bugs and potential vulnerabilities.